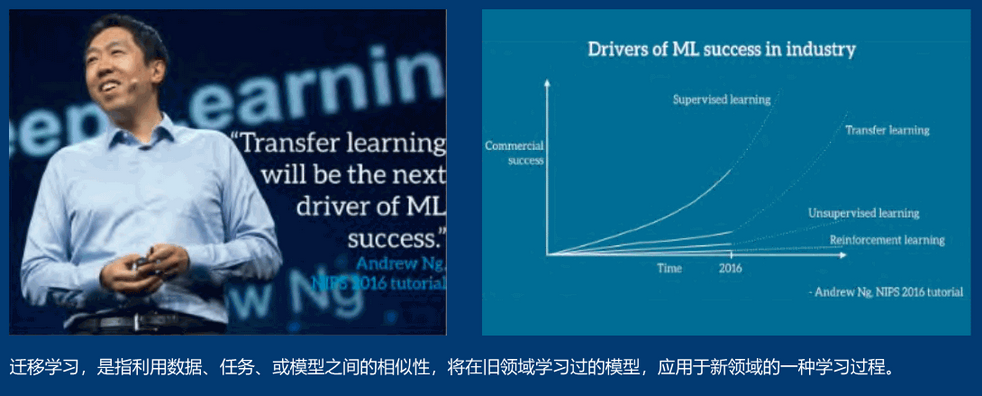
什么是迁移学习
迁移学习,简单来讲就是机器能够“举一反三”,例如本来能够分辨猫和狗的神经网络在经过少量的训练后能够很好地分辨老虎和狮子,这就叫迁移学习。迁移学习可以将在一个领域训练的机器学习模型应用到另一个领域,在某种程度上提高了训练模型的利用率,解决了数据缺失的问题。迁移学习使不依赖于大数据的深度学习成为可能。
有了迁移学习,我们便可以将神经网络像软件模块一样进行拼装和重复利用。例如,而我们可以将在大数据集上训练好的大型网络迁移到小数据集上,从而只需经过少量的训练就能达到良好的效果。我们也可以将两个神经网络同时迁移过来,组成一个新的网络,这两个神经网络就像软件模块一样被组合了起来。
迁移学习的由来
监督学习要求训练集和测试集上的数据具有相同的分布特性。而迁移学习允许训练集和测试集的数据有不同的分布、目标甚至领域。
迁移学习的意义
未来,随着迁移学习的大量应用,可能会出现一种新的商业形态:大公司运用大数据训练大模型,再将这些模型迁移到小公司擅长的特定垂直领域中。以语音识别为例:大公司可以运用大规模语料训练打的语音识别模型,这种模型在99%的日常应用场景中能达到很高的准确度,但是对于一个充斥着大量专业术语的学术会议的情景,这种通用的语音识别模型可能识别98%的常用词汇,但是另外2%的学术术语反而是这个学术会议的关键。在这种情境下,如果结合大语音识别模型,运用迁移学习技术,再去训练一个专门针对数学领域的语音识别模型,则有可能实现关键性的突破。
运用神经网络实现迁移学习
深度神经网络会在不同的层学到数据中不同尺度的信息,所以可以将不同的层视作不同尺度的特征提取器。
迁移学习方式一般可分为预训练模式和固定值模式:
- 预训练模式:将迁移过来的权重视作新网络的初始权重,在训练的过程中会被梯度下降算法改变数值。
- 固定值模式:迁移过来的部分网络在结构和权重上都保持固定的数值,训练过程进针对迁移模块后面的全连接网络
其中固定值模式需要调节的参数少,学习的收敛速度理论上会更快。我们应根据实际问题的需要选择使用更适合的迁移学习模式。
迁移大型卷积神经网络:
——蚂蚁还是蜜蜂
下面我们动手实现迁移学习:区分画面上的动物是蚂蚁还是蜜蜂

ResNet与模型迁移
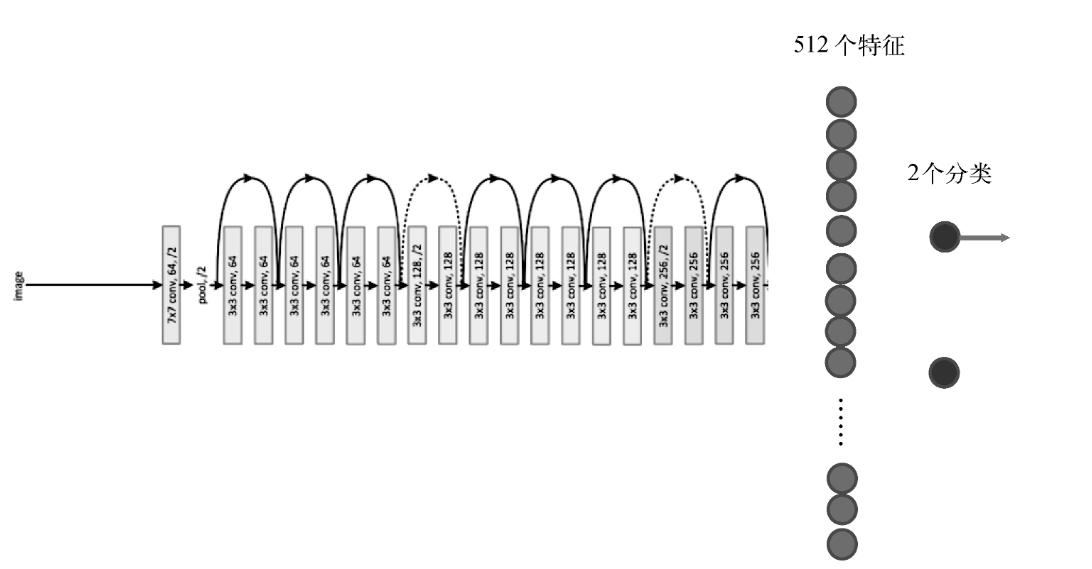
我们迁移一个18层的残差网络精简版(ResNet)。残差网络是一种特殊的卷积神经网络,有152层,在物体分类等任务上具有较高的准确度。
pytorch提供多种层数(18/34/50/101/152)的ResNet模型,都已经是在ImageNet数据集上训练完毕的网络,因此可以直接拿来进行迁移学习。
我们的新模型是一个深层的ResNet与两层全连接的组合。如下图所示:
代码实现
以下分别用预训练和固定值方式对这个深度网络进行训练:
- 导入所有需要的包
1 | #加载程序所需要的包 |
- 加载需要的数据
一、加载数据
运用PyTorch的dataset来加载硬盘上的大量图像
只要我们将大量的图像文件都放入指定的文件夹下(训练数据集在data/train下面,校验数据集在data/val下面)
并且将不同的类别分别放到不同的文件夹下。例如在这个例子中,我们有两个类别:bees和ants,我就需要在硬盘上
建立两个文件夹:bees和ants。
我们只需将相应的训练数据和校验数据图像放到这两个文件夹下就可以用datasets的ImageFolder方法自动加载
1 | # 从硬盘文件夹中加载图像数据集 |
1 | def imshow(inp, title=None): |
运行的效果如下:

二、加载一个卷积神经网络作为对比
1 | # 用于手写数字识别的卷积神经网络 |
运行结果:
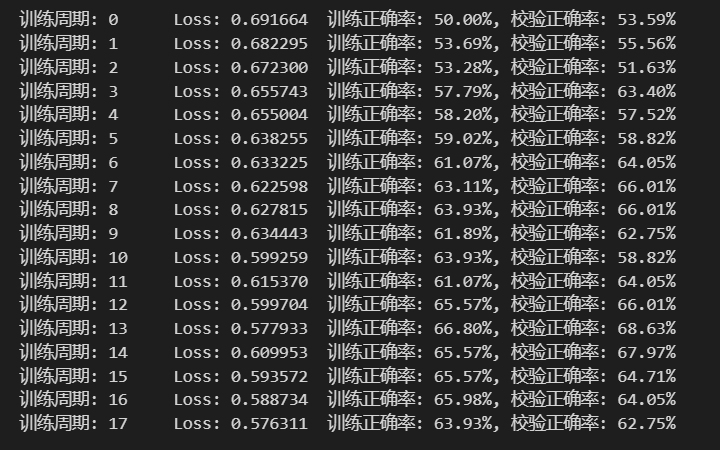
在测试集上分批运行,并计算总的正确率
1 | #在测试集上分批运行,并计算总的正确率 |
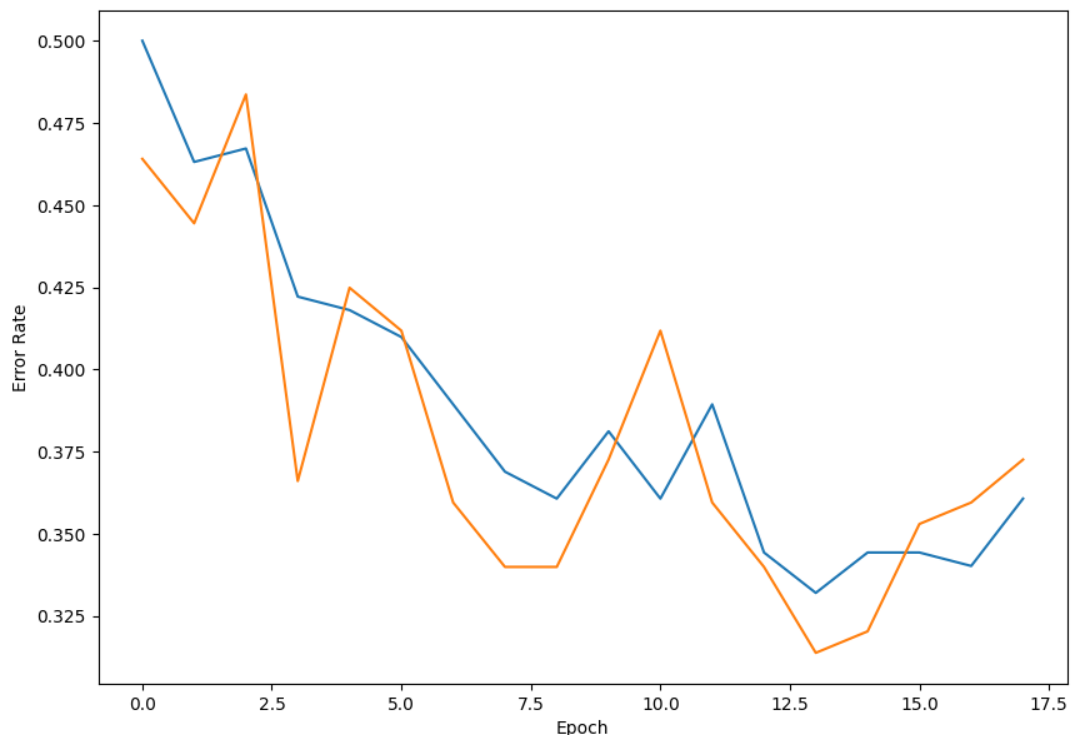
绘制误差率曲线:
1 | # 绘制误差率曲线 |
运行结果: