1.运行1-5程序时,我的Devc++运行的结果和书上作者的运行结果,还有我的VS上的运行结果都出现了一些差异:
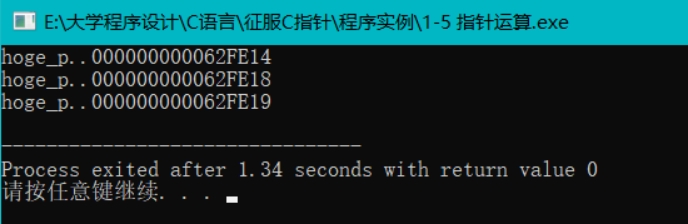
1)作者的运行结果中将指向Int的指针类型强制转化为(void*)类型后进行了hoge_p+1,得到的结果仍是加了一个Int类型字节的长度,即地址数值增加了十六进制下的‘4’
2)在我的dev中程序出现警告:
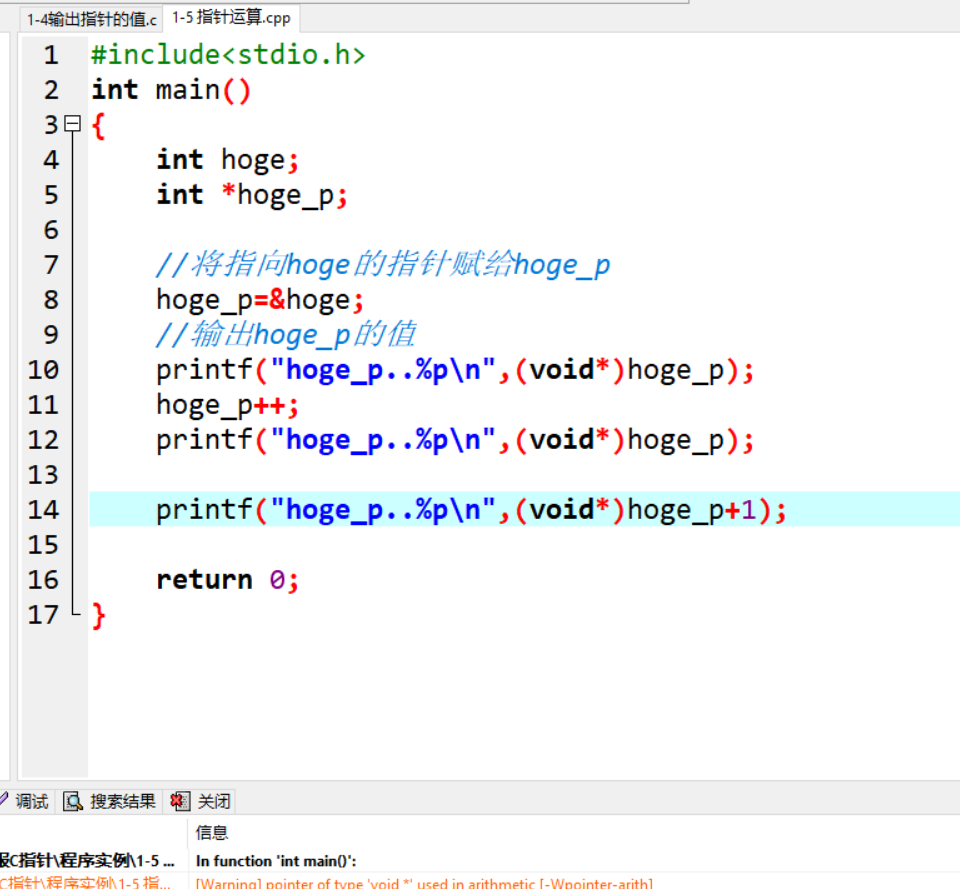
其实并没有理解这句警告是什么意思,大致是告诉我说前面已经定义了该指针是指向Int的,但是后面又做了强制类型转换,会出现一些意外;果然,当我运行的时候发现第14行的输出语句输出的值竟真的只是十六进制下hoge_p的地址值+十六进制下的数字‘1’:
1)VS 2019对此的警告级别较高,不允许对未知指向类型的指针进行运算



这里发现11行的赋值语句能够正常给该指针值加上一个(int)类型字节长度的值,是因为在开始就定义了该指针指向int,12行的输出语句在强制类型转换的时候没有对指针值进行运算,这里默认还是按照指针指向int来输出,因此前两个大概没有报错;第十四行我们发现在强制类型转换的时候又对指针值进行了运算操作,这时候就会给程序造成指令上的矛盾,为了保护之后程序的正常运行,报错处理!
2)VS中对于上图中第14行代码如果将红框中运算改成[(void*)hoge_p++],仍会输出hoge_p原来的值;
2. 代码1-10中关于文件数组操作的一些学习心得:
里面的部分文字和图片出处:CSDN博客
(1)关于函数fgets():
l 虽然用 gets() 时有空格也可以直接输入,但是 gets() 有一个非常大的缺陷,即它不检查预留存储区是否能够容纳实际输入的数据,换句话说,如果输入的字符数目大于数组的长度,gets 无法检测到这个问题,就会发生内存越界,所以编程时建议使用 fgets()。(C程序中的文件操作内容我是真的一点也没有学,所以此处对gets()和fgets()都很陌生,所以既然先遇到了fgets()就先了解一下它吧,gets()后面遇到再说;)
l Fgets();的原型:

它的功能是从 stream 流中读取 size 个字符存储到字符指针变量 s 所指向的内存空间。它的返回值是一个指针,指向字符串中第一个字符的地址。标准输入流 stdin指的是输入缓冲区(暂时不深入了解)
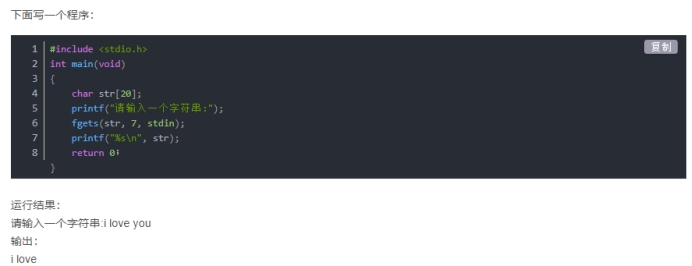
fget() 函数中的 size 如果小于字符串的长度,那么字符串将会被截取;如果 size 大于字符串的长度则多余的部分系统会自动用 ‘\0’ 填充。所以假如你定义的字符数组长度为 n,那么 fgets() 中的 size 就指定为 n–1,留一个给 ‘\0’ 就行了。但是需要注意的是,如果输入的字符串长度没有超过 n–1,那么系统会将最后输入的换行符 ‘\n’ 保存进来,保存的位置是紧跟输入的字符,然后剩余的空间都用 ‘\0’ 填充。所以此时输出该字符串时 printf 中就不需要加换行符 ‘\n’ 了,因为字符串中已经有了。
程序示例:
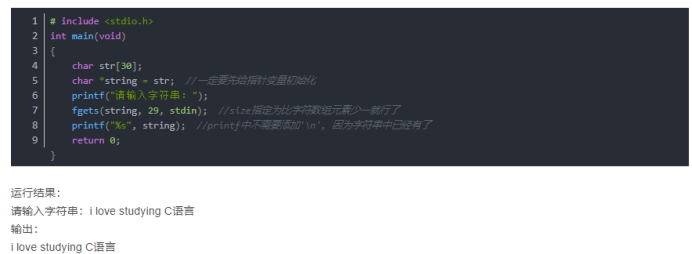
fgets() 和 gets() 一样,最后的回车都会从缓冲区中取出来。只不过 gets() 是取出来丢掉,而 fgets() 是取出来自己留着。但总之缓冲区中是没有回车了!所以与 gets() 一样,在使用 fgets() 的时候,如果后面要从键盘给字符变量赋值,那么同样不需要清空缓冲区。
(2) 关于EOF:
如果是文本,一般文本文件的结尾是以ascii码25表示的,你读到这个字符,也可以认为文本文件结束了.eof函数查看最后一次读文件是否为文件的最后一个记录,是,返回非零,否,返回零。eof可以不加括号。(暂且就了解这么多吧继续往下看书)
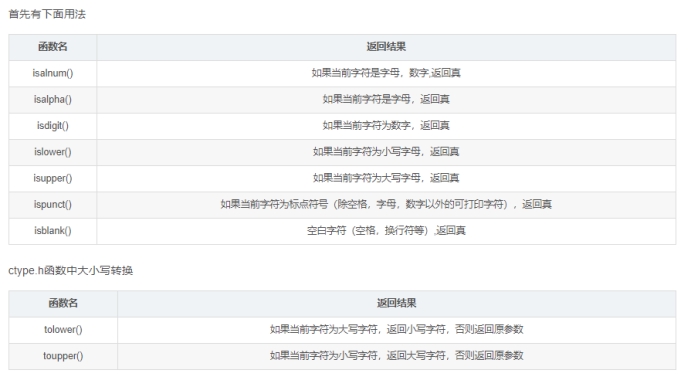
(3)C语言的宏isalnum(ctype.h):
(3) 关于exit()函数:
exit(): 结束当前进程/当前程序/,在整个程序中,只要调用 exit ,就结束。
return() 是当前函数返回,当然如果是在主函数main, 自然也就结束当前进程了,如果不是,那就是退回上一层调用。在多个进程时.如果有时要检测上进程是否正常退出的.就要用到上个进程的返回值。
exit(1)表示进程正常退出. 返回 1;
exit(0)表示进程非正常退出. 返回 0.
(4)关于getc(fp):

(4) 关于fprintf():
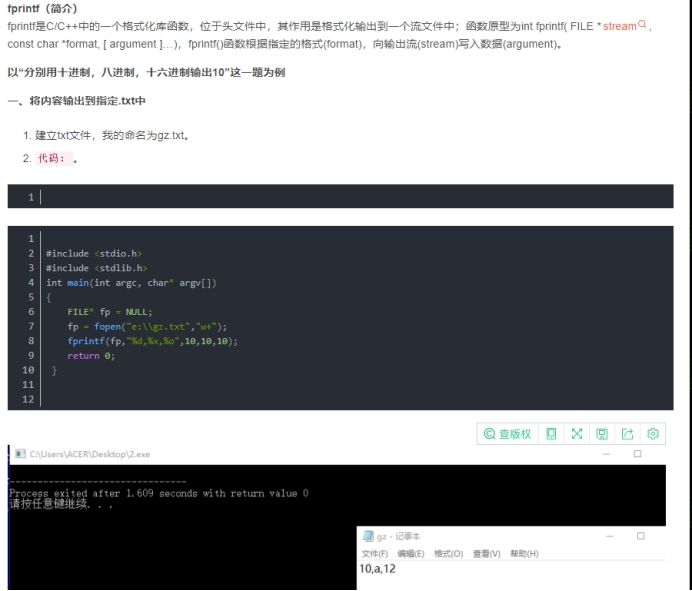

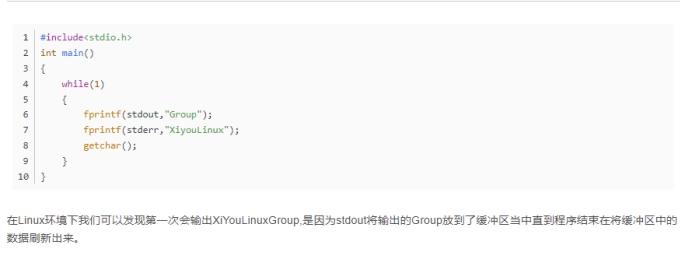
关于Fprintf(stdout)和fprintf(stderr):
stdout(标准输出),输出方式是行缓冲。输出的字符会先存放在缓冲区,等按下回车键时才进行实际的I/O操作。
stderr(标准错误),是不带缓冲的,这使得出错信息可以直接尽快地显示出来。


到这里还没有理解1-10的代码···未完待续
现在是1月11号我又来学习了
(很开心第一件事就是理解了上次卡住我的1-10代码,耗时40ish minutes);
3.17日学习
(1)运行程序1-11可变长数组时出现了如下结果:
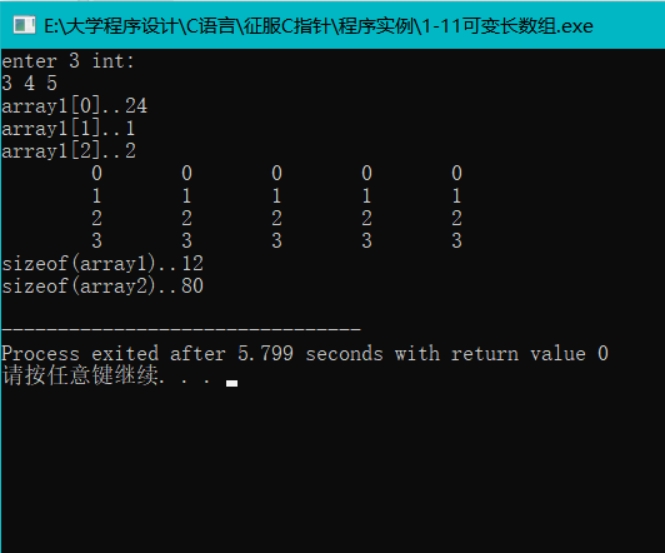
这与书上的结果简直大相径庭,array[0]本应该是0,却出现了24.。。。。Array2的结果也是完全不同。由于时间关系先往下学习吧。深究这个机会成本有点大。
(2) 程序2-1
(3) fgets()函数
(4) 关于sscanf()函数:
首先我们先来看函数定义:
定义函数 int sscanf (const char str,const char * format,……..);
函数说明
sscanf()会将参数str的字符串根据参数format字符串来转换并格式化数据。格式转换形式请参考scanf()。转换后的结果存于对应的参数内。
返回值 成功则返回参数数目,失败则返回-1,错误原因存于errno中。 返回0表示失败 否则,表示正确格式化数据的个数 例如:sscanf(str,”%d%d%s”, &i,&i2, &s); 如果三个变成都读入成功会返回3。 如果只读入了第一个整数到i则会返回1。证明无法从str读入第二个整数。
定义太抽象了,我们还是先来看一下常见的用法吧:
(1)sscanf(“zhoue3456 “, “%4s”, str); //取指定长度的字符串
printf(“str=%s\n”, str); //str=”zhou”;
(2)sscanf(“zhou456 hedf”, “%[^ ]”, str); //取到指定字符为止的字符串,取遇到空格为止字符串
printf(“str=%s\n”, str); //str=zhou456;
(3)sscanf(“654321abcdedfABCDEF”, “%[1-9a-z]”, str); //取仅包含指定字符集的字符串
printf(“str=%s\n”, str); //str=654321abcded,只取数字和小写字符
(4)sscanf(“BCDEF123456abcdedf”, “%[^a-z]”, str); //取到指定字符集为止的字符串
printf(“str=%s\n”, str); // str=BCDEF123456, 取遇到大写字母为止的字符串
(5)int a,b,c;
sscanf(“2015.04.05”, “%d.%d.%d”, &a,&b,&c); //取需要的字符串
printf(“a=%d,b=%d,c=%d”,a,b,c); // a=2015,b=4,c=5
通过上面这几个例子相信大家对sscanf的用法会有一个直观的理解了,下面我们再来看一下更复杂一些的例子:
(6)给定一个字符串“abcd&hello$why”,现在我想取出&与$之间的字符串怎么办呢
sscanf(“abcd&hello$why”, “%[^&]&%[^$]”, str );printf(“str=%s\n”,str); //str=”hello”
其中%[]类似于一个正则表达式,如[a-z]表示读取所有a-z的字符,[^a-z]表示读取所有非小写字母的字符。那么在这里%*[^&]表示先过滤掉abcd,然后以&隔开,后面还剩hello$why,然后将$之前非$的字符提取到str中。
(7)给定一个字符串“what, time”,如果我想仅保留time,那该怎么办呢?(,后面有个空格)
sscanf(“what, time”, “%*s%s”, str );printf(“str=%s\n”,str); //str=”time”
其中%*s表示第一个被匹配到的字符串what,被过滤掉了,如果没有空格,则结果为NULL。其实“what, time”被空格分割成了两个字符串”what,”和”time”.
然而有人会问,C语言中的scanf和sscanf有什么区别和联系呢?OK,sscanf和scanf确实很类似,两者都是用于输入。只是后者以屏幕stidin为输入源,而前者是以字符串为输入源,仅此而已。
函数原型:int scanf( const char *format [,argument]… );
其中的format可以是一个或多个